
Greetings friends,
Let’s set one thing straight:
Most portfolios are built on Kaggle datasets and passion projects.
That’s why they blend in.
Hiring managers don’t care about “projects.” They care about business impact.
If you don’t have work experience, you need to be deliberate about what you build. What gets attention today are skills that solve real problems in real teams.
Here is what that looks like:
- Core skills remain non-negotiable: Python, SQL, machine learning, and data visualization.
- Storytelling is rising: companies want candidates who can explain insights clearly, not just run analysis.
- Data readiness is critical: expect to work with SQL and cloud data warehouses like BigQuery or Snowflake.
- Deployment and AI awareness are emerging: you don’t need to be an engineer, but knowing how models reach production and how generative AI is being used will set you apart.
I’ll break it down and show you what projects to focus on.
1 . Data Visualization
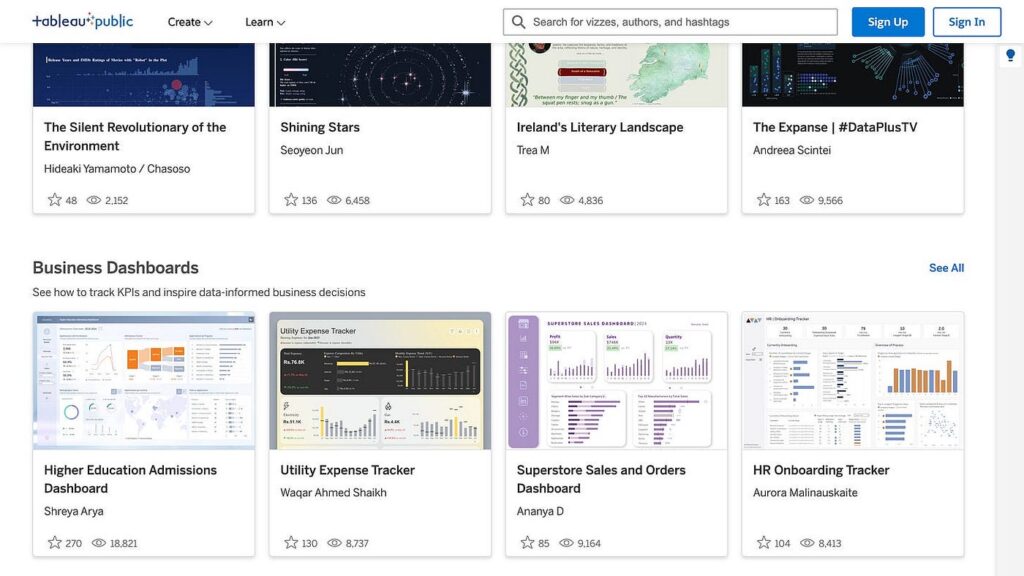
A key job of a Data Scientist is championing data democratization so your visualization skills must go beyond matplotlib.
Your portfolio should prove two things:
- Exploration: peers and non-technical stakeholders can use your visuals to uncover insights.
- Storytelling: you can connect findings into a clear narrative, choosing visuals that guide your audience and highlight the “so what.”
Show this by including BI tools. Modern data teams rely on them, and they demonstrate you can turn insights into decisions.
2 . Exploratory Data Analysis (EDA)
EDA is where you turn messy data into something usable. It’s more than a first step, it’s often an iterative cycle you return to as new questions come up.
Strong EDA in your portfolio shows that you can:
- Spot outliers, trends, and missing values.
- Test simple hypotheses and compare distributions.
- Loop back and refine preprocessing when needed.
It also shows that you can go beyond running models and actually understand the story the data is telling.
3 . Data Engineering
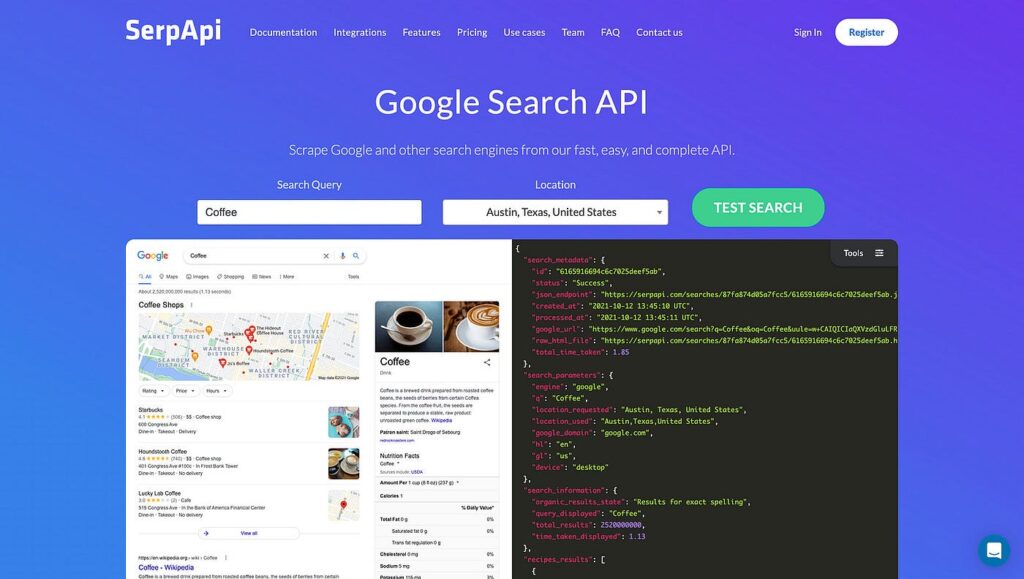
Few mention this, but Data Science isn’t just building predictive models. You need a broad skill set and experience with data collection and processing is non-negotiable.
Why? Many companies lack a dedicated data engineering team, and even if they have one, it’s still your job to ensure data is available and high quality.
Data collection can mean API calls, experiments, or web scraping. Data processing might involve SQL modeling or cloud platforms like BigQuery.
Mastering these proves you’re not just building models, you’re building them on solid ground.
4 . Applied Machine Learning & Analytics
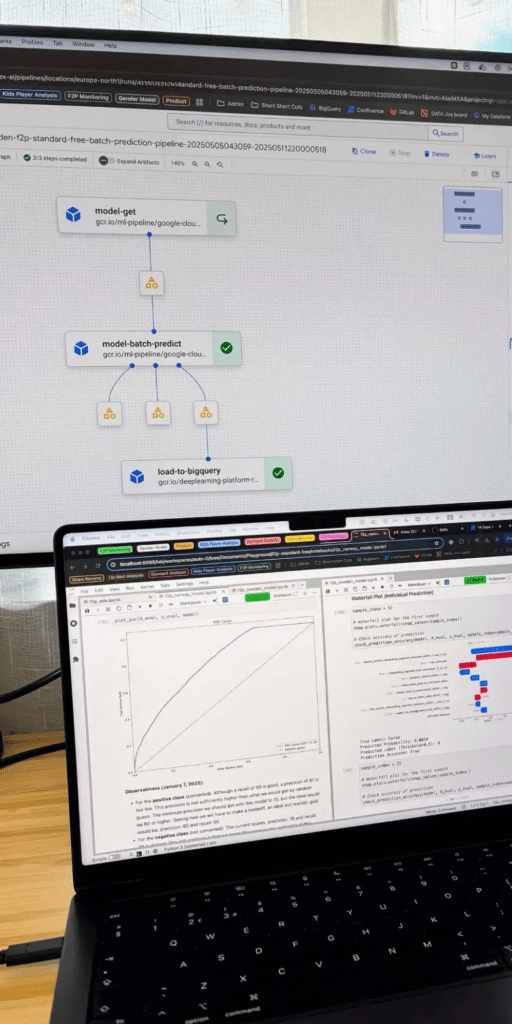
This is where you move beyond exploration and prove you can solve problems with data. Employers want to see not just analysis, but the ability to apply stats and ML to drive decisions.
In practice, that means:
- Stats: regression, hypothesis testing, causal inference.
- ML: predictive models with scikit-learn, TensorFlow, or PyTorch.
- Experimentation: design and evaluate A/B tests.
- Deployment awareness: package models as APIs, run Docker, or use cloud services.
You’re not expected to be an ML engineer, but knowing the lifecycle, from analysis to deployment, sets you apart. End-to-end projects often span multiple skills, just like real work.
The Projects
By now, you should see that what projects you choose and how you execute them makes all the difference in bridging the experience gap and catching a hiring manager’s eye.
To make it concrete, let’s tackle the most common questions about which projects to build.
1. Which types of projects should I choose?
The strongest projects check these boxes:
- That you can solve a real business problem.
- That you can take the project end-to-end.
- That you can demonstrate one or more of the core competencies.
Think of your portfolio as a puzzle. Each project should clearly highlight different strengths, and together they should cover the full picture.
2. What exactly are end-to-end projects?
An end-to-end project mirrors how data science work happens inside companies. It does not stop at cleaning data or training a model. It shows you can:
- Pull and prepare messy data
- Explore and analyze it effectively
- Build and evaluate a model or solution
- Deliver results in a usable form, such as a dashboard, API, or deployment
For example:
- A dashboard project should start with collecting and exploring the data before moving into visualization.
- A customer churn project should include the entire pipeline, from pulling customer data to deploying a simple prediction service.
3. Which business problems exactly?
There are endless business problems to tackle, but the best projects depend on the industry you want to work in.
If tech is your goal, three areas are always safe bets:
- Marketing: measure campaigns, optimize spend, understand behavior.
- Sales: forecast revenue and improve pipeline efficiency.
- Customer: retention, churn, and lifetime value are core metrics
Where do I find good datasets?
One of the most common questions I get is about datasets—and the answer has changed. Kaggle is fine for basics, but it doesn’t reflect how data science works in real teams.
Employers now expect you to handle data as it really comes: messy, incomplete, and from external sources. That’s why your projects should include:
- APIs for live data
- Web scraping to build datasets
- Cloud-hosted data at real-world scale
This shift reflects the overlap with data engineering and MLOps. Collecting and preparing your own data shows you’re ready for real workflows, not classroom exercises.
The takeaway
You don’t need ten projects or every trending tool you hear about in social media. You need a few well-chosen, strategic, end-to-end projects that prove you can do the work of a data scientist.
That is how you bridge the experience gap and stand out in today’s market.
Best of luck
Abi